图像识别笔记
这个主要记录算法迭代的过程
1NN
import numpy as np
from data_utils import load_CIRFA10
class NearestNeighbor(object):
def __init__(self) -> None:
pass
def train(self, X, y):
self.Xtr = X
self.ytr = y
def predict(self, X):
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype=self.ytr.dtype)
for i in range(num_test):
distances = np.sum(np.abs(self.Xtr - X[i, :]), axis=1)
min_index = np.argmin(distances)
Ypred[i] = self.ytr[min_index]
return Ypred
def main():
Xtr, Ytr, Xte, Yte = load_CIRFA10("cifar-10-batches-py")
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3)
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3)
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
Yte_predict = nn.predict(Xte_rows)
print("精度为: %f" % (np.mean(Yte_predict == Yte)))
if __name__ == "__main__":
main()
kNN
import numpy as np
from data_utils import load_CIRFA10
class NearestNeighbor(object):
def __init__(self, k = 5):
self.k = k
def train(self, X, y):
self.Xtr = X
self.ytr = y
def predict(self, X):
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype=self.ytr.dtype)
k = int(self.k)
if k <= 0:
raise ValueError("k must be >= 1")
if k > self.Xtr.shape[0]:
raise ValueError("k cannot be larger than number of training smaples")
for i in range(num_test):
distances = np.sum(np.abs(self.Xtr - X[i, :]), axis=1)
knn_idx = np.argpartition(distances, k - 1)[:k]
knn_labels = self.ytr[knn_idx]
Ypred[i] = np.bincount(knn_labels, minlength = 10).argmax()
return Ypred
def main():
Xtr, Ytr, Xte, Yte = load_CIRFA10("cifar-10-batches-py")
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3)
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3)
for i in range(1, 10):
knn = NearestNeighbor(k=i)
knn.train(Xtr_rows[:10000], Ytr[:10000])
Yte_predict = knn.predict(Xte_rows[:500])
print("%d 精度为: %f" % (knn.k, np.mean(Yte_predict == Yte[:500])))
if __name__ == "__main__":
main()
笔者搜了一下,这里我们只调用了cpu的算力,没有用到显卡,所以进行了修改,让训练可以利用显卡的算力,代码如下
kNN改
import cupy as np # 调用cupy
from data_utils import load_CIRFA10
import time
class NearestNeighbor(object):
def __init__(self, k = 5):
self.k = k
def train(self, X, y):
self.Xtr = np.asarray(X) # 转到GPU
self.ytr = np.asarray(y)
def predict(self, X):
X = np.asarray(X)
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype=self.ytr.dtype)
k = int(self.k)
if k <= 0:
raise ValueError("k must be >= 1")
if k > self.Xtr.shape[0]:
raise ValueError("k cannot be larger than number of training smaples")
for i in range(num_test):
distances = np.sum(np.abs(self.Xtr - X[i, :]), axis=1)
knn_idx = np.argpartition(distances, k - 1)[:k]
knn_labels = self.ytr[knn_idx]
Ypred[i] = np.bincount(knn_labels, minlength = 10).argmax()
return Ypred
def main():
start_time = time.perf_counter()
Xtr, Ytr, Xte, Yte = load_CIRFA10("cifar-10-batches-py")
# 展平,然后防止unit8做差会溢出,转为float32
Xtr_rows = Xtr.reshape(Xtr.shape[0], -1).astype(np.float32)
Xte_rows = Xte.reshape(Xte.shape[0], -1).astype(np.float32)
Ytr = np.asarray(Ytr) # 放到GPU中
Yte = np.asarray(Yte)
for i in range(1, 10):
knn = NearestNeighbor(k=i)
knn.train(Xtr_rows[:10000], Ytr[:10000])
Yte_predict = knn.predict(Xte_rows[:500])
# 结果转为 CPU 再算
acc = float(np.mean(Yte_predict == Yte[:500]).get())
print("%d 精度为: %f" % (knn.k, acc))
end_time = time.perf_counter()
print("总用时: %.4f s" % (end_time - start_time))
if __name__ == "__main__":
main()
可以得到
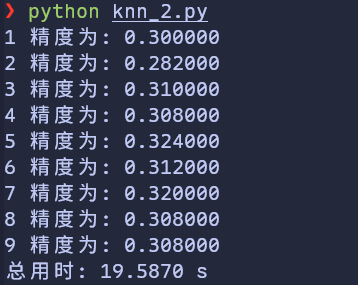
那么再看看 cpu 算呢
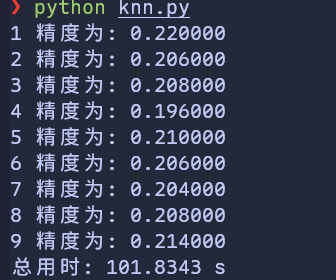
时间减小为 ⅕,精度还提升了。
不过精度为什么还提升了,我们并没有优化算法不是吗
分析
我的猜测:
- 我们从 Numpy 切换到 CuPy 后,虽然算法没有发生改变,但是数值精度发生了变化
- cpu 和 gpu 的计算方法不同
Numpy 默认使用的是 float64,而我的knn_2使用的是 float32,一个是15位,另一个是7位。而算 L1 距离的时候我们要对 3072 维数据做累加,一些极小的舍入可能造成很大的误差
做一下实验,看看猜测是否合理:我的实验设计是将原本的 knn.py 中改为float32; knn_2.py 中改为float64。结果为:
float32位的gpu计算、floa64位的gpu计算和float32位的cpu计算得到了一样的结果,且与未指明精度的cpu结果不同
根据gpu两次不同精度结果来看,float32和float64的差异并未构成区别,说明不是float64和float32的问题。
从float32的cpu与gpu对比来看,cpu和gpu的架构或者别的什么并未构成区别,说明不是两者计算方法的问题
不过,我有注意到,cpu算float32时用的时间比未指明精度用的时间长,我猜测我这里的numpy可能默认用的精度更低。测试一下 print(Xtr_rows.dtype, Xte_rows.dtype, Ytr.dtype)。输出结果如下:

破案了,其实是 uint8 的问题。
为什么呢?个人猜测如下:
uint8 相减会出现underflow。比如,10-250 因为表示方法的问题变为了 16,导致结果其实完全不正确,所以才出现了这么低的精度答案
那么改为int16试试,正数范围没变,但是多了负数的处理。
结果 发现,与float32的gpu等计算结果一样了,那么应该就是这个问题,即无符号整数的underflow情况
以及笔者尝试了一下 uint16,各位看到这里可以猜一下 acc(准确率) 是高了些还是低了?以及为什么?
答案
acc低到了随机猜测的范围,也就是 0.1 左右。原因其实很好想,uint8的时候我们对负数模256,uint16的时候要模65296,这会导致距离计算的误差变得更大,导致训练结果无限趋近于随机猜测
此外
既然float32和float64的结果一样。我猜测float64的精度已经溢出,那么float32的精度是不是也溢出了呢?尝试将gpu的float32改为int8,看看结果如何
非常的令人振奋!不仅速度快了,精度也获得了提升
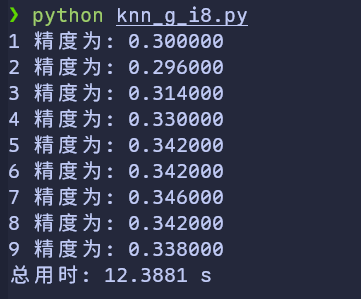
应该是-128~127的小范围把L1距离做了压缩,改变了一些近邻结构,更详细的我就不理解了
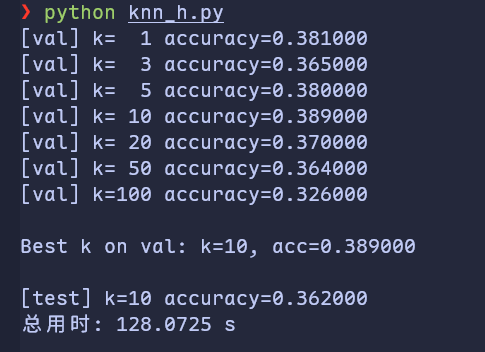
超参数调优
import cupy as np # 调用cupy
from data_utils import load_CIRFA10
import time
class NearestNeighbor(object):
def __init__(self, k=5):
self.k = k
def train(self, X, y):
self.Xtr = np.asarray(X) # 转到GPU
self.ytr = np.asarray(y)
def predict(self, X):
X = np.asarray(X)
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype=self.ytr.dtype)
k = int(self.k)
if k <= 0:
raise ValueError("k must be >= 1")
if k > self.Xtr.shape[0]:
raise ValueError("k cannot be larger than number of training smaples")
for i in range(num_test):
distances = np.sum(np.abs(self.Xtr - X[i, :]), axis=1)
knn_idx = np.argpartition(distances, k - 1)[:k]
knn_labels = self.ytr[knn_idx]
Ypred[i] = np.bincount(knn_labels, minlength=10).argmax()
return Ypred
def main():
start_time = time.perf_counter()
Xtr, Ytr, Xte, Yte = load_CIRFA10("cifar-10-batches-py")
# 展平,然后防止uint8做差会溢出,转为float32
Xtr_rows = Xtr.reshape(Xtr.shape[0], -1).astype(np.float32)
Xte_rows = Xte.reshape(Xte.shape[0], -1).astype(np.float32)
# 放到GPU中
Ytr = np.asarray(Ytr)
Yte = np.asarray(Yte)
# ====== 结合“超参数调优”逻辑:划分验证集 ======
Xval_rows = Xtr_rows[:1000, :]
Yval = Ytr[:1000]
Xtr_rows_train = Xtr_rows[1000:, :]
Ytr_train = Ytr[1000:]
# ====== 在验证集上选最好的 k ======
validation_accuracies = []
k_candidates = [1, 3, 5, 10, 20, 50, 100]
for k in k_candidates:
nn = NearestNeighbor(k=k) # 最小改动:k 走构造器
nn.train(Xtr_rows_train, Ytr_train)
Yval_predict = nn.predict(Xval_rows)
# GPU -> CPU 再算标量
acc = float(np.mean(Yval_predict == Yval).get())
print(f"[val] k={k:3d} accuracy={acc:.6f}")
validation_accuracies.append((k, acc))
best_k, best_acc = max(validation_accuracies, key=lambda t: t[1])
print(f"\nBest k on val: k={best_k}, acc={best_acc:.6f}\n")
# ====== 用 best_k 在 test 上评估(示例:仍取前500个 test) ======
final_nn = NearestNeighbor(k=best_k)
final_nn.train(Xtr_rows_train, Ytr_train)
Yte_predict = final_nn.predict(Xte_rows[:500])
test_acc = float(np.mean(Yte_predict == Yte[:500]).get())
print(f"[test] k={best_k} accuracy={test_acc:.6f}")
end_time = time.perf_counter()
print("总用时: %.4f s" % (end_time - start_time))
if __name__ == "__main__":
main()