图像识别
这是一堂入门讲座,旨在向计算机视觉领域以外的人们介绍图像份额里问题以及数据驱动方法。目录:
- 图像分类
- 最近邻分类器
- k-最近邻分类器
- 用于超参数调优的验证集
- 摘要
- 摘要:kNN的实际应用
- 延伸阅读
图像分类
动机:这一节中我们将会介绍图像分类问题,这是一个将输入的图片分配到一个固定类别集合中的一个标签的任务。这是计算机视觉任务的核心问题之一,尽管简单,但依旧有各种各样的应用。此外,就像我们将在课程后面看到的,许多其它看似不同的计算机视觉任务(例如目标检测、分割)都可以简化为图像分类
示例:例如,在下图中,一个图像分类模型接受一个简单的任务,并生成该图片属于集合{cat ,dog,hat,mug}中各个标签的概率。需要注意的是,对于计算机来说,一张图片由一个巨大的3维数组构成。在这个示例中,这只猫猫图像的宽度为 248 像素,高度为 400 相似,并且有 3 个颜色通道红、绿、蓝(简称RGB)。因此,这个图像由 \(248\times 400\times 3\) 个数字组成,总计 \(297,600\) 个数字。每个数字是一个介于 0 (黑色)到 255 (白色)的整数。而我们的任务就是把这二十万个数字转换为一个标签,例如“cat”
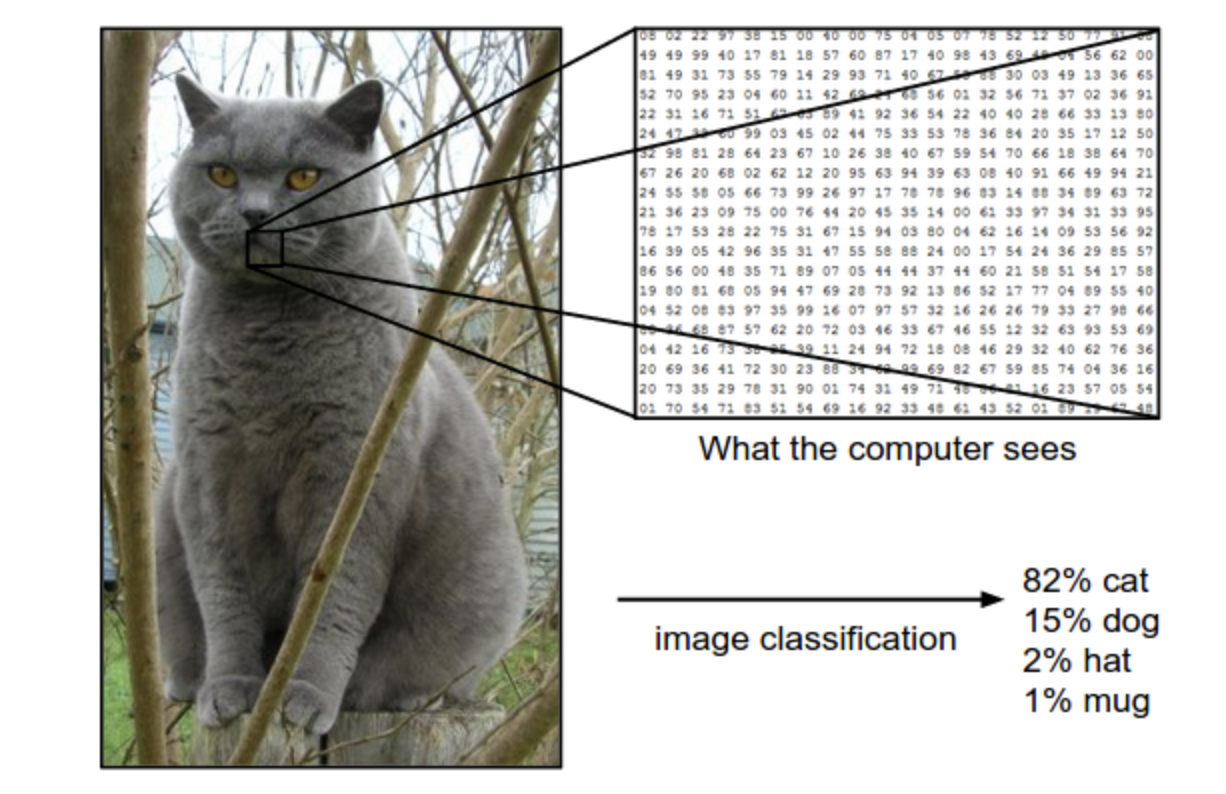
图像分类任务就是为给定的图片预测一个标签(或者像这里给出一系列可能的标签的概率)。图像是0 ~ 255 范围的 3 维数组,尺寸为 \(宽度\times 高度 \times 3\)。其中 3 代表红绿蓝三个颜色通道
困难:尽管对人类来说,识别出一个像“猫”这样的视觉概念是一件相当简单的事,但是从计算机视觉算法的角度思考就是一个值得考虑的挑战了。在下面我们例举了一些计算机视觉遇到的挑战,请时刻记住,图像的原始表示形式是一个形式为亮度值的 3 维数组:
- 视角变化:对于单个物体来说,可以有多个摄像角度
- 大小变化:物体可视大小经常出现变化(这里同样指现实世界的大小,而不仅是图像中的)
- 形变 Deformatino:很多物体的形状不是一成不变的,可以表现为多种形式
- 遮挡 Occlusion:物体的形状可能被遮挡。有时只有物体的一小部分(甚至几个像素)可以被看到
- 光照条件 Illumination conditions:在像素层面上,光照的影响非常大
- 背景杂乱 Background clutter:物体可能混入背景之中,导致难以识别
- 类内差异 Intra-class variation:一类物体的形状差异可能非常大,例如 椅子。这类物体有许多不同的对象,都有自己独特的形状
在上述条件交织下,一个好的图像识别模型必须能维持分类结论稳定的同时,保持对类间差异的敏感

数据驱动方法。如何写一个图像识别算法呢?这与写一个数字排序算法不同,我们是搞不清楚如何写一个从图片中认出一个猫的算法的。因此,与其在代码写明每一种物体的形状,不如像我们对待孩子那样:我们可以给计算机提供大量类别示例,然后开发一个学习算法去看这些例子,并学习每一个类别的视觉外形。这个方法就是 数据驱动方法。既然该方法的第一步是收集已经做好分类标注的图片来作为 训练集,那么我们来看一下数据集的样子:

一个用于 4 个视觉类别的训练集。事实上我们可能有数以千计的类别,每个类别还有成千上万的图片
图片分类流程。我们知道,图像识别就是输入一个元素为像素值的数组,然后给它分配一个分类标签。完整流程如下:
- 输入:输入是包含了 N 个图像的几何,每个图片的标签是 K 个分类标签中的一种。我们称这些数据为 训练集(training set)
- 学习:我们的任务是使用训练集去学习每一种分类长什么样。称这一步为 训练分类器 或 学习模型
- 评价:最后,让分类器学习它之前从未见过的图像,并以此来评价分类器的质量。我们将这些图像的正确标签与分类器的预测标签做对比。毫无疑问,我们希望更多的预测可以符合正确答案(称为 ground truth)
最近邻分类
作为课程介绍的第一个方法,我们将尝试实现一个最近邻分类器。这个分类器和CNN(卷积神经网络)没有任何关系,实际中也很少使用。但通过实现它,我们可以理解图像识别问题的基本方法
图像分类数据集:CIFAR-10:一个常见的图像分类数据集是 CIFAR-10 dataset。这个数据集有 60,000 张 32像素高、32像素宽的小图片。每个图片的标签是 10 个分类标签中的一种。这 6 万张图片分为包含 5 万张图片的训练集和包含 1 万张图片的测试集。下图中你可以看到 10 个类的10张随机图片

左:来自 CIFAR-10 dataset 的样例。右:第一列是测试图像,然后第一列的每个测试图像右边是使用最近邻分类算法。根据像素差异,从训练集中选出 10 张最类似的图片
假设我们现在有CIFAR-10的 5 万张图片(每种分类 5000 张)作为训练集,我们希望将剩下的 1 万张打上标签。最近邻分类器将拿着测试图片去和每一个训练图像比较。并将它认为最接近的训练图片的标签赋给这张测试图片。可以注意到上面的 10 个测试中只有 3 个预测正确。比如第 8 行中,马头被分类为一个红色的跑车,可能是因为强烈的黑色背景,和马的图片接近,于是被错误地分类为汽车。
你可能注意到我们没有指明如何比较两个图片的细节,在本例中,我们比较的是两个 \(32\times 32\times 3\) 的像素块。其中一个最简单的方法就是一个像素一个像素的比较,然后把差别加到一起。换句话说,就是把两张图片先转化为两个向量 \(I_1、I_2\), 而比较合适的选择就是 \(L_1\) 距离:
然后我们对所有像素点求和,下图是过程可视化:

以图片中的一个颜色通道作为示例。用 \(L_1\) 距离计算两张图片之间的区别。逐个像素求差值,然后全部相加。如果两张图片完全相同,那么结果将会为0;同样的,如果两个图片非常不同,那么结果将非常的大
接下来让我们看一下这个分类器如何代码实现。首先,我们将 CIFAR-10 的数据加载到内存中,并分为 4 个数组:训练数据/标签和测试数据/标签。在下面的代码中,Xtr 包含了训练集的所有图片(大小为 \(50,000\times 32\times 32\times 3\)),Ytr 是对应的长度为 50000 的 1 维数组,存有图像对应的分类标签(从0到9)
Xtr, Ytr, Xte, Yte = load_CIRFAR10('data/cifar10/') # a magic function provided
# flatten out all images to be one-dimensional
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3) # Xtr_rows becomes 50,000 * 3072
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3) # Xte_rows becomes 10,000 * 3072
现在我们得到了所有图片的数据,并把它们拉长为行向量。接下来我们训练和评估分类器
nn = NearestNeighbor() # 创建一个最近邻分类器对象
nn.train(Xtr_rows, Ytr) # 根据训练图像和标签,训练分类器
Yte_predict = nn.predict(Xte_rows) # 根据测试图像预测标签
# 打印出来正确预测平均值作为分类准确性
print "accuracy: %f" % ( np.mean(Yte_predict == Yte) )
使用准确率(accuracy)作为评估标准是很常见的,它描述了预测正确的得分。请注意以后我们实现的所有分类器必须使用这个常用API: train(x,y) 函数。这个函数使用训练集的数据和标签来进行训练。从内部来看,类应该实现一些关于标签和标签如何被预测的模型。同时有一个 predict(X) 函数,它的作用就是预测新输入数据的标签。当然,我们现在忽略了一些东西——分类器的实现。下面是使用 \(L_1\) 距离的最近邻分类器的实现讨论:
import numpy as np
class NearestNeighbor(object):
def __init__(self):
pass
def train(self, X, y):
"""
X: (N, D) training data
y: (N,) training labels
"""
self.Xtr = X
self.ytr = y
def predict(self, X):
"""
X: (M, D) test data
returns: (M,) predicted labels
"""
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype=self.ytr.dtype)
for i in range(num_test):
distances = np.sum(np.abs(self.Xtr - X[i, :]), axis=1) # (N,)
min_index = np.argmin(distances)
Ypred[i] = self.ytr[min_index]
return Ypred
如果运行这个代码,会发现这个分类器在 CIFAR-10 的准确率只有 38.6%。比随机猜测的 10% 高了很多,但比人类的识别水平(推测约为94%)或卷积神经网络的95% 差多了。(可以在这里看CIFAR-10的 Kaggle 竞赛排行榜)
距离选择:有许多方式计算两个向量之间的距离。另一种常见的替代方法是 \(L_2\) 距离。从几何学的角度来看,它在计算两个向量之间的欧氏距离。距离计算公式如下:
换句话说,我们依旧是计算像素点的差值,只是先求其平方,然后把这些平方全部加起来,最后对这个和开方。在numpy中,我们只需要简单替换一行即可:
distances = np.sqrt(np.sum(np.squqre(self.Xtr - X[i,:]),axis = 1))
这里虽然使用了 np.sqrt ,但是在实际中可能不用。因为求平方根是一个单调函数,它对不同距离的绝对值求平方根虽然改变了数值大小,但依然保持了不同距离大小的顺序。所以用不用都能对像素差异的大小进行正确比较。如果将这个模型用于 CIFAR-10 数据集,将可以得到 35.4% 的准确率(略低于 L1 距离的结果)
L1 vs. L2。比较这两个距离计算方式的区别挺有意思的。事实上,当面对两个不同向量的差异时,L2 距离比 L1 距离更不能容忍。也就是说,L2 距离更倾向于多个中等程度的差异而不是1个巨大差异。L1 和 L2 距离都是在 p-norm 常用的特殊形式
效果展示
由于笔者没有什么算力支持,所以仅截取了前面的部分数据集进行训练和预测,得到了0.18的精度(),下面是笔者的完整代码
# nn.py
import numpy as np
from data_utils import load_CIRFA10
class NearestNeighbor(object):
def __init__(self) -> None:
pass
def train(self, X, y):
self.Xtr = X
self.ytr = y
def predict(self, X):
num_test = X.shape[0]
Ypred = np.zeros(num_test, dtype=self.ytr.dtype)
for i in range(num_test):
distances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)
min_index = np.argmin(distances)
Ypred[i] = self.ytr[min_index]
return Ypred
def main():
Xtr, Ytr, Xte, Yte = load_CIRFA10('cifar-10-batches-py')
Xtr_rows = Xtr.reshape(Xtr.shape[0], 32 * 32 * 3)
Xte_rows = Xte.reshape(Xte.shape[0], 32 * 32 * 3)
nn = NearestNeighbor()
nn.train(Xtr_rows[:2000], Ytr[:2000])
Yte_predict = nn.predict(Xte_rows[:200])
print ("accuracy: %f" % (np.mean(Yte_predict == Yte[:200])))
if __name__ == "__main__":
main()
# data_utils.py
import os
import pickle
import numpy as np
def load_CIFAR_batch(filename):
with open(filename, "rb") as f:
datadict = pickle.load(f, encoding="bytes")
X = datadict[b"data"]
y = datadict[b"labels"]
X = X.reshape(10000, 3, 32, 32).transpose(0, 2, 3, 1)
y = np.array(y, dtype=np.int64)
return X, y
def load_CIRFA10(root):
xs, ys = [], []
for i in range(1, 6):
f = os.path.join(root, f"data_batch_{i}")
X, y = load_CIFAR_batch(f)
xs.append(X)
ys.append(y)
Xtr = np.concatenate(xs, axis=0)
Ytr = np.concatenate(ys, axis=0)
Xte, Yte = load_CIFAR_batch(os.path.join(root, "test_batch"))
return Xtr, Ytr, Xte, Yte